- 满分: 100
- 及格分: 60
单选题
题目 1
在信创环境下,以下哪个步骤是安装Hadoop前的必要准备?
- A. 安装Java环境
- B. 配置网络
- C. 安装MySQL
- D. 创建Kubernetes集群
题目 2
在D3.js中,以下哪个方法用于选择页面上的元素?
- A. select
- B. querySelector
- C. getElementById
- D. find
题目 3
使用Flume收集日志数据时,如果遇到网络波动导致数据传输中断,以下哪种策略可以帮助恢复数据?
- A. 内存缓存
- B. 文件系统缓存
- C. 数据库缓存
- D. Redis缓存
题目 4
在Vue.js中,以下哪个生命周期钩子在组件销毁之前调用?
- A. beforeCreate
- B. beforeMount
- C. beforeDestroy
- D. destroyed
题目 5
在使用Hive进行数据查询时,以下哪个命令用于创建一个新表?
- A. CREATE TABLE
- B. NEW TABLE
- C. INSERT TABLE
- D. ADD TABLE
题目 6
在容器环境中搭建大数据平台时,如果遇到性能瓶颈,以下哪个策略可能最有效?
- A. 增加容器数量
- B. 优化Hadoop配置
- C. 使用更快的存储设备
- D. 升级网络带宽
题目 7
关于在信创环境下容器环境中搭建大数据平台,以下哪项说法是正确的?
- A. 大数据平台搭建不需要考虑容器的网络配置
- B. 搭建过程中不需要对相关组件进行可用性验证
- C. 大数据平台的搭建需要安装和配置Hadoop、Spark等组件
- D. 容器环境中搭建的大数据平台不支持分布式计算
题目 8
以下哪个工具与其他工具在功能上不同?
- A. HDFS
- B. MapReduce
- C. YARN
- D. Docker
题目 9
如果在容器环境中搭建的大数据平台出现数据丢失问题,最可能的原因是?
- A. 容器资源不足
- B. HDFS配置错误
- C. 网络延迟
- D. 存储设备故障
题目 10
在Spark中,以下哪个操作可以用来合并两个RDD中的元素?
- A. union()
- B. join()
- C. Cogroup()
- D. combineByKey()
题目 11
以下哪种语言不是Hadoop生态系统中的主要编程语言?
- A. Java
- B. Scala
- C. Python
- D. Ruby
题目 12
在Flink中,以下哪个算子用于对数据流进行时间窗口操作?
- A. reduce
- B. aggregate
- C. window
- D. apply
题目 13
以下哪个Vue.js指令用于条件性地渲染元素?
- A. v-if
- B. v-show
- C. v-else
- D. v-for
题目 14
以下哪个端口是Hadoop默认的NameNode服务端口?
- A. 50070
- B. 8088
- C. 9000
- D. 2181
题目 15
在处理分类问题时,如果类别标签是连续的,应该使用哪种算法?
- A. 回归分析
- B. 分类算法
- C. 聚类算法
- D. 关联规则学习
题目 16
以下哪个算法属于无监督学习?
- A. 神经网络
- B. 随机森林
- C. K-均值聚类
- D. 逻辑回归
题目 17
在Hive中,若要计算一个字段的总和,应使用哪个HiveQL函数?
- A. SUM()
- B. COUNT()
- C. AVG()
- D. MAX()
题目 18
Kafka中的Producer负责什么功能?
- A. 消费消息
- B. 保存消息
- C. 发送消息
- D. 监控消息
题目 19
在使用支持向量机(SVM)进行分类时,以下哪个核函数可以用来处理非线性问题?
- A. 线性核
- B. 多项式核
- C. RBF核
- D. Sigmoid核
题目 20
在Kafka中,以下哪个操作可以增加Topic的分区数?
- A. kafka-topics —create
- B. kafka-topics —alter
- C. kafka-topics —list
- D. kafka-topics —describe
题目 21
在Flink中,以下哪个组件负责接收数据源的数据?
- A. Flink JobManager
- B. Flink TaskManager
- C. Flink DataStream
- D. Flink Source
题目 22
在监督学习中,如果模型在训练数据上表现很好,但在测试数据上表现不佳,这可能是什么问题?
- A. 过拟合
- B. 欠拟合
- C. 数据不均衡
- D. 特征不足
题目 23
以下哪个步骤是数据预处理的一部分?
- A. 特征选择
- B. 模型评估
- C. 参数调优
- D. 数据可视化
题目 24
在Flink中,以下哪个组件负责将数据写入到外部系统?
- A. Flink Sink
- B. Flink Source
- C. Flink Transform
- D. Flink Window
题目 25
在Hadoop集群中,如果有3个DataNode,每个DataNode存储1TB数据,那么整个集群存储的数据总量是多少?
- A. 1TB
- B. 2TB
- C. 3TB
- D. 4TB
题目 26
以下哪个库提供了Python中的机器学习算法?
- A. NumPy
- B. pandas
- C. scikit-learn
- D. Matplotlib
题目 27
使用Vue.js时,如果要监听某个属性的变化,应该使用以下哪个选项?
- A. v-watch
- B. v-on
- C. watch
- D. computed
题目 28
在Spark中,RDD代表什么?
- A. Resilient Distributed Dataset
- B. Resilient Data Distribution
- C. Random Data Distribution
- D. Reliable Distributed Database
题目 29
在随机森林算法中,以下哪个参数可以用来控制树的深度?
- A. max_features
- B. min_samples_split
- C. max_depth
- D. n_estimators
题目 30
使用Flume进行数据采集时,如果需要保证数据不丢失,应该选择哪种Agent部署模式?
- A. 单节点Agent
- B. 多节点Agent
- C. 复制节点Agent
- D. 负载均衡Agent
题目 31
在处理REST API响应时,以下哪个JavaScript对象用于存储和传输数据?
- A. ArrayBuffer
- B. Blob
- C. JSON
- D. FormData
题目 32
关于Hadoop中的MapReduce,以下哪项描述是正确的?
- A. MapReduce主要用于实时数据处理
- B. MapReduce只能处理结构化数据
- C. MapReduce包含Map和Reduce两个处理阶段
- D. MapReduce不支持分布式计算
题目 33
在Hive中,若要删除一个表,应使用的命令是______。
- A. DROP TABLE
- B. DELETE TABLE
- C. REMOVE TABLE
- D. ERASE TABLE
题目 34
在REST风格的API中,以下哪个HTTP方法通常用于获取资源?
- A. POST
- B. GET
- C. PUT
- D. DELETE
题目 35
在Vue.js中,以下哪个指令用于绑定HTML元素的数据属性?
- A. v-text
- B. v-bind
- C. v-model
- D. v-html
题目 36
在Spark中,以下哪个操作最适合对数据进行聚合?
- A. map()
- B. reduce()
- C. reduceByKey()
- D. groupByKey()
题目 37
当使用Scala进行Flink数据流分析时,以下哪种数据类型最适合表示事件时间戳?
- A. Int
- B. Long
- C. String
- D. Timestamp
题目 38
以下哪种算法通常用于分类问题?
- A. 线性回归
- B. 决策树
- C. K-均值聚类
- D. 主成分分析
题目 39
在处理大量数据时,以下哪种情况可能导致Spark作业失败?
- A. 内存不足
- B. 磁盘空间不足
- C. 网络延迟
- D. 所有以上选项
题目 40
在Kafka中,以下哪个概念用于实现消息的持久化?
- A. Topic
- B. Partition
- C. Offset
- D. Replica
题目 41
以下哪个Vue.js组件用于创建可复用的自定义元素?
- A. Vue.component
- B. Vue.extend
- C. Vue.mixin
- D. Vue.directive
题目 42
在JavaScript中,以下哪个库用于在浏览器中进行数据可视化?
- A. D3.js
- B. jQuery
- C. React
- D. Angular
题目 43
在神经网络中,如果输出层的激活函数是Sigmoid,那么输出层的值范围是多少?
- A. [0, 1]
- B. [-1, 1]
- C. [负无穷, 正无穷]
- D. [0, 正无穷]
题目 44
在Spark中,哪个Transformation操作不会触发实际的计算?
- A. map()
- B. filter()
- C. flatMap()
- D. persist()
题目 45
以下哪个JavaScript库用于绘制图表?
- A. Chart.js
- B. Math.js
- C. Moment.js
- D. Lodash
题目 46
以下哪个算法用于推荐系统中的协同过滤?
- A. K-最近邻
- B. 主成分分析
- C. 决策树
- D. 梯度提升机
题目 47
在信创环境下,以下哪个组件是搭建大数据平台不可或缺的?
- A. Docker
- B. Kubernetes
- C. Hadoop
- D. MySQL
题目 48
在容器环境中搭建大数据平台时,以下哪个命令用于启动Hadoop的NameNode服务?
- A. start-dfs.sh
- B. start-yarn.sh
- C. start-hadoop.sh
- D. start-namenode.sh
题目 49
关于Hadoop中的YARN,以下哪项描述是正确的?
- A. YARN是Hadoop的资源管理系统
- B. YARN用于存储大数据
- C. YARN是一个容器编排工具
- D. YARN用于网络通信
题目 50
在Flink中,以下哪个算子用于将数据流转换为表?
- A. flatMap
- B. map
- C. toTable
- D. fromElements
多选题
题目 1
以下哪些是无监督学习算法?
- A. 主成分分析
- B. K-均值聚类
- C. 层次聚类
- D. 线性回归
题目 2
以下哪些是常用的监督学习算法?
- A. 决策树
- B. 支持向量机
- C. 随机森林
- D. K-均值聚类
题目 3
以下哪些是Apache Spark的核心特性?
- A. 快速处理
- B. 易于使用
- C. 容错性
- D. 适用于批量处理
题目 4
在Spark中,以下哪些是RDD(弹性分布式数据集)的转换操作?
- A. map
- B. filter
- C. reduce
- D. count
题目 5
以下哪些是Vue.js中的核心概念?
- A. 数据绑定
- B. 组件
- C. 路由
- D. Vuex
题目 6
以下哪些描述正确地定义了Kubernetes中的Pod?
- A. Pod是一组容器的集合
- B. Pod是Kubernetes中最小的部署单元
- C. Pod可以运行多个容器
- D. Pod总是包含一个主容器
- E. Pod可以共享网络和存储资源
题目 7
在Hadoop生态系统中,以下哪些组件用于数据存储?
- A. HDFS
- B. HBase
- C. Hive
- D. YARN
题目 8
在进行数据预处理时,以下哪些步骤是常见的?
- A. 数据清洗
- B. 特征选择
- C. 特征工程
- D. 数据标准化
题目 9
以下哪些组件是搭建大数据平台时常用的?
- A. Hadoop
- B. Docker
- C. Kubernetes
- D. MySQL
- E. MongoDB
题目 10
在容器化的大数据平台中,以下哪些步骤是安装Hadoop集群的必要步骤?
- A. 安装Java运行环境
- B. 配置网络
- C. 安装Docker
- D. 配置Hadoop配置文件
- E. 启动所有容器
题目 11
在使用Vue.js进行数据可视化时,以下哪些库是常用的?
- A. D3.js
- B. Chart.js
- C. ECharts
- D. Highcharts
题目 12
在Flink中,以下哪些是常用的数据源连接器?
- A. Kafka
- B. RabbitMQ
- C. Twitter
- D. Elasticsearch
题目 13
如果需要在容器环境中部署HDFS,以下哪些操作是必要的?
- A. 创建HDFS配置文件
- B. 启动NameNode容器
- C. 启动DataNode容器
- D. 安装Apache ZooKeeper
- E. 配置YARN
题目 14
以下哪些是Apache Flink的主要特性?
- A. 高吞吐量
- B. 低延迟
- C. 流处理和批处理统一
- D. 强状态管理
题目 15
在使用Kafka时,以下哪些是正确的?
- A. Kafka是一个分布式流处理平台
- B. Kafka支持高吞吐量的数据流
- C. Kafka只能用于消息队列
- D. Kafka可以保证数据不丢失
题目 16
以下哪些是Flume的主要组件?
- A. Agent
- B. Collector
- C. Master
- D. Sink
题目 17
在Vue.js中,以下哪些是声明式渲染的例子?
- A. v-text
- B. v-html
- C. v-for
- D. v-if
题目 18
以下哪些是Vue.js中的生命周期钩子?
- A. created
- B. mounted
- C. updated
- D. destroyed
题目 19
以下哪些是评估分类模型性能的指标?
- A. 准确率
- B. 精确率
- C. 召回率
- D. F1分数
题目 20
在使用Hive进行数据分析时,以下哪些操作可以用来优化查询性能?
- A. 使用分区表
- B. 使用索引
- C. 使用物化视图
- D. 使用MapReduce
判断题
题目 1
Flume是一种用于日志收集和聚合的工具,它可以保证数据传输的可靠性。
- A. 正确
- B. 错误
题目 2
以下陈述是正确的:Hadoop的MapReduce计算框架不支持迭代计算。
- A. 正确
- B. 错误
题目 3
在决策树中,信息增益总是优于基尼不纯度作为特征选择的准则。
- A. 正确
- B. 错误
题目 4
关于Kubernetes的陈述:Kubernetes可以用于自动化容器化的应用程序的部署、扩展和管理。
- A. 正确
- B. 错误
题目 5
随机森林算法不会受到过拟合的影响,因为它是一种集成学习方法。
- A. 正确
- B. 错误
题目 6
在监督学习中,支持向量机(SVM)是一种用于分类和回归分析的算法。
- A. 正确
- B. 错误
题目 7
以下说法是正确的:在容器中部署Hadoop集群时,NameNode和DataNode可以运行在同一个容器中。
- A. 正确
- B. 错误
题目 8
以下陈述是正确的:在容器环境中搭建大数据平台时,Docker是唯一可用的容器技术。
- A. 正确
- B. 错误
题目 9
以下说法是正确的:Hive不支持自定义函数(UDF)。
- A. 正确
- B. 错误
题目 10
D3.js是一个独立的可视化库,它可以在不依赖Vue.js的情况下使用。
- A. 正确
- B. 错误
题目 11
使用Vue.js进行数据可视化时,必须先安装Vue.js库才能在项目中使用。
- A. 正确
- B. 错误
题目 12
关于Spark的陈述:Spark比Hadoop MapReduce在内存计算上更加高效。
- A. 正确
- B. 错误
题目 13
在Vue.js中,数据绑定是通过v-bind指令实现的,而事件绑定是通过v-on指令实现的。
- A. 正确
- B. 错误
题目 14
Flink是一个用于有界数据流处理的框架。
- A. 正确
- B. 错误
题目 15
Kafka是一个分布式流处理平台,它主要用于处理实时数据流。
- A. 正确
- B. 错误
综合题
题目 1
智能交通领域利用大数据优化城市交通流量和缓解拥堵策略是一个关键问题。下面绘制了一个折线图,确定一些关键的数据维度,比如不同时间段的交通流量、拥堵情况、道路使用效率等。这些维度可以帮助我们全面了解智能交通系统的效果。
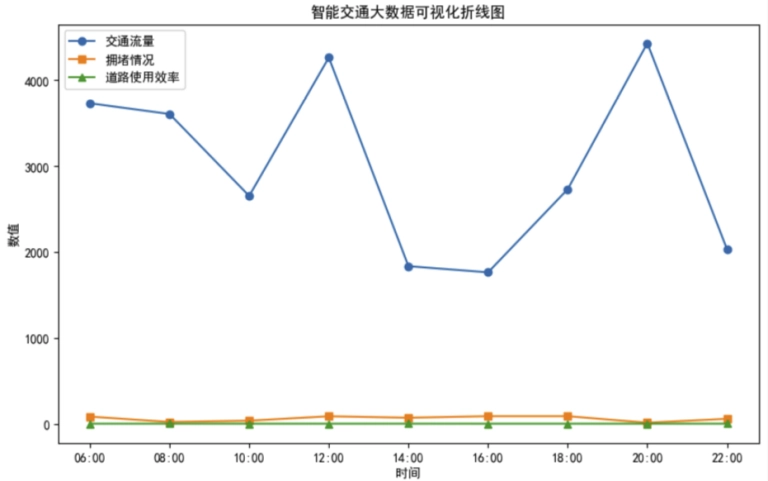
请你依据绘制的“智慧交通大数据可视化折线图”,用简洁的语言陈述其所表达的相关问题;
题目 2
零售大数据 在零售行业中,了解不同产品类别的销售比例对于制定精准营销策略至关重要。下面绘制一个饼图/环形图,我将使用数据来展示不同产品类别的销售比例。这个图表将帮助我们理解各个产品类别在整体销售额中的占比,从而指导营销资源的分配和优化产品组合。
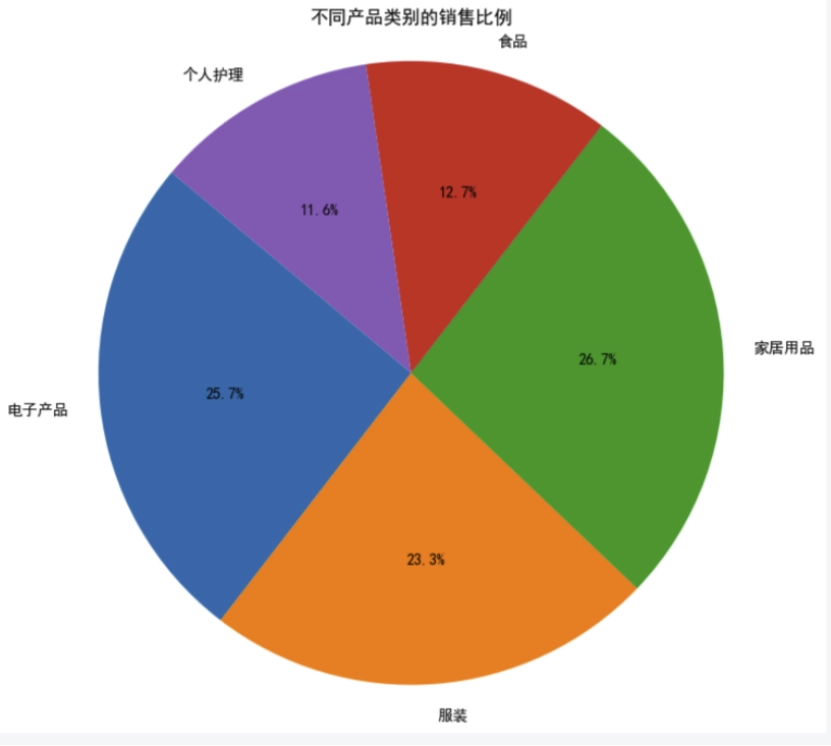
请你依据绘制的“不同产品类别销售比例”,用简洁的语言陈述其所表达的相关问题:
题目 3
智慧医疗 在智慧医疗领域,大数据的分析对于疾病预测和健康管理至关重要。下面绘制了一个雷达图,一些关键的医疗数据维度,比如疾病预测准确性、健康风险评估、个性化治疗方案的有效性、患者依从性和远程监测效率等。这些维度可以帮助我们全面了解智慧医疗服务在不同方面的表现和特征。 这是一个基于智慧医疗领域大数据的雷达图。在这个图表中,不同的轴代表不同的智慧医疗数据维度,包括疾病预测准确性、健康风险评估、个性化治疗方案的有效性、患者依从性和远程监测效率。数据点在各个维度上的分布通过雷达图的形式展现出来,从而可以直观地了解智慧医疗服务在不同方面的表现和特征。
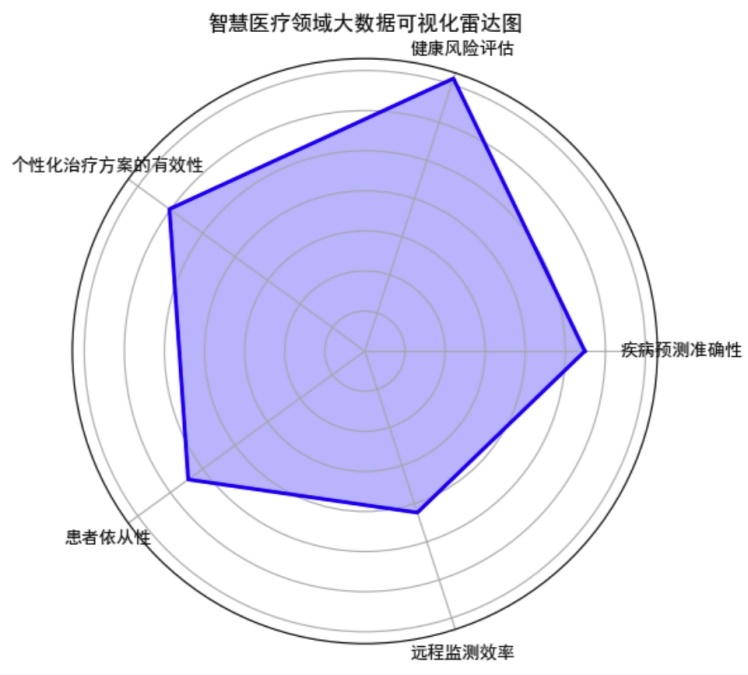
请你依据绘制的“智慧医疗领域大数据可视化雷达图”,用简洁的语言陈述其所表达的相关问题;