样题说明:本样题,依据决赛竞赛规程中关于竞赛模块要求设计,仅供参考;
竞赛实操环境说明:
(切记:正式比赛,请您根据比赛环境的相关说明在服务器环境中搭建分布式集群环境,并 填写相关答案;备赛情况,请依据题目要求自行搭建环境)
| 序号 | 配置项 | 详细信息 |
|---|---|---|
| 1 | 操作系统 | 中科方德服务器操作系统 |
| 2 | HDFS | 已安装 |
| 3 | 软件位置 | /home/zkpk/soft |
| 4 | 服务器 | 1 主节点(主机名:master ) |
| 2 计算节点: | ||
| 节点1: slave01 | ||
| 节点2: slave02 | ||
| 5 | 用户名,密码 | 用户包含: root、zkpk;密码:zkpk |
一、大数据平台搭建模块(20 分,共 20 个题目,每小题 1 分)
题目 1
在执行 SSH 密钥生成命令 ssh-keygen -t rsa 后,生成的公钥文件路径为 ____。
答案
答案:~/.ssh/id_rsa.pub
题目 2
在启动 HDFS 之前,需要在 master 节点上对 HDFS 进行格式化操作,使用的命令为 ____。
答案
答案:hdfs namenode -format
题目 3
如果需要配置 Hadoop 的开机自启动脚本,可以在文件 /etc/rc.d/rc.local 中添加启动命令,并确保该文件具有执行权限。命令为 ____。
答案
答案:chmod +x /etc/rc.d/rc.local
题目 4
启动 HDFS 和 YARN 服务的命令分别为 ____ 和 ____。
答案
答案:start-dfs.sh 和 start-yarn.sh
题目 5
在中科方德系统中,为了赋予 zkpk 用户 sudo 权限,可以通过编辑 /etc/sudoers 文件,并添加以下内容: ____。
答案
答案:zkpk ALL=(ALL) NOPASSWD: ALL
题目 6
检查 HDFS 文件系统的运行状态(如剩余空间、集群健康状况等),使用的命令为 ____。
答案
答案:hadoop fs -report
题目 7
检查 HDFS 的当前状态和健康情况的命令为 ____。
答案
答案:hdfs dfsadmin -report
题目 8
退出 HDFS 安全模式,可以使用的命令是 ____。
答案
答案:hdfs dfsadmin -safemode leave
题目 9
在 Hive 的 hive-site.xml 文件中,配置连接元数据存储的 JDBC 驱动时, javax.jdo.option.ConnectionURL 的值应设置为 jdbc:mysql://master:3306/____。
答案
答案:hive
题目 10
启动 Hive 服务时,可以使用 hiveservice 命令启动 Hive Metastore 服务,命令是 ____。
答案
答案:metastore
题目 11
在 Hive 元数据初始化阶段,使用的命令是 schematool -dbType ____ -initSchema。
答案
答案:mysql
题目 12
HBase 依赖于 Zookeeper,因此在 hbase-env.sh 文件中,我们将 HBASE_MANAGES_ZK 设置为 ____,以禁用 HBase 自带的 Zookeeper 管理功能。
答案
答案:false
题目 13
启动 HBase 集群的命令是 ____,这将自动启动 HBase 及其内置的 Zookeeper。
答案
答案:start-hbase.sh
题目 14
在主节点上查看 HBase 是否启动,可以使用 jps 命令检查进程列表,确保显示 ____ 和 HRegionServer。
答案
答案:HMaster
题目 15
在 HBase 中删除表之前,需要先禁用该表,可以使用命令 ____ 'test_table' 禁用表,然后用 drop 'test_table' 删除表。
答案
答案:disable
题目 16
为了与 Hive 集成,需要将 Hive 的 ____ 文件复制到 Spark 的 conf 目录中。
答案
答案:hive-site.xml
题目 17
在 Spark SQL 中,可以执行 SHOW TABLES; 命令来查看集成的 Hive 表,随后可以使用 ____ FROM your_hive_table LIMIT 10; 来查询表内容。
答案
答案:SELECT
题目 18
在 Spark Shell 中,可以使用 sc.parallelize 函数创建一个并行集合,比如 val data = sc.parallelize(1 to 1000),然后通过 ____ 方法计算元素数量。
答案
答案:count()
题目 19
启动 Spark Master 服务的命令是 ____,该命令会启动 Spark 主节点。
答案
答案:start-master.sh
题目 20
如果 Spark 使用 MariaDB 作为 Hive 的元数据存储,需要确保 MariaDB 的 JDBC 驱动文件位于 Spark 的 ____ 目录下。
答案
答案:jars
二、离线数据处理(30 分,每空 3 分,共 10 题)
智慧学习项目
1. 项目背景描述
本项目旨在利用离线数据分析探索智慧学习领域的数据。智慧学习结合大数据分析和人工智 能技术,通过对学生学习数据的分析与挖掘,可以优化教学过程,提升教学质量,个性化学 习体验。项目将会从学习数据中挖掘行为模式、学习进度、学习成果等信息,帮助教育机构 和教师更好地理解学生需求,为教育决策提供数据支持。
2. 使用的技术
- **HDFS(Hadoop Distributed File System)**:用于分布式存储大量学习数 据文件,保证数据的安全和可靠性。
- **Hive**:数据仓库工具,支持对学习数据进行结构化查询和分析,便于使用 SQL 操作数据。
- **ZooKeeper**:用于分布式系统的协调和管理,保障系统组件之间的通信与一致性。
- **HBase**:NoSQL 数据库,用于存储结构化数据,适合快速读写大量数据,支持数 据的高并发访问。
- **Spark**:分布式计算框架,处理学习数据的分析任务,特别适合大规模数据处理和 复杂计算。
- **Python**:作为编程语言用于数据加载、分析和结果呈现。
- **PyCharm**:开发环境(IDE),提高 Python 开发效率并简化调试过程。
3. study.csv 文件数据结构与格式说明
- **文件名**:
study.csv - **记录数**:100 条
- **数据结构**:文件包含学习行为的相关数据字段,每条记录代表一名学生或一次学习 活动。以下是
study.csv的字段说明: student_id:学生唯一标识符course_id:课程唯一标识符study_date:学习日期,格式为YYYY-MM-DDstudy_time:学习时长(分钟)activity_type:学习活动类型(如”阅读”、“练习”、“测验”)score:测验或练习分数(如果适用)completion_status:完成状态(如”已完成”、“未完成”)
数据示例
student_id,course_id,study_date,study_time,activity_type,score,completion_status
S001,C101,2024-10-01,45,阅读,,已完成
S002,C102,2024-10-01,30,练习,85,已完成
S003,C101,2024-10-02,50,测验,90,已完成
...4. 项目目录结构
以下是项目的建议目录结构:
smart_learning_analysis/
├── data/
│ └── study.csv # 原始学习数据文件
│
├── src/
│ ├── __init__.py # 初始化文件
│ ├── data_loader.py # 数据加载模块
│ ├── data_analysis.py # 数据分析主模块
│ ├── hive_integration.py # Hive 查询与数据整合模块
│ └── hdfs_operations.py # HDFS 读写操作模块
│
├── config/
│ └── config.yaml # 配置文件(如 HDFS、Hive、Spark 等相关配置)
│
├── results/
│ └── analysis_output.csv # 分析结果文件(包含学习行为的统计结果)
│
├── logs/
│ └── analysis.log # 运行日志
│
└── README.md # 项目说明文档5. 项目主要功能模块说明
- data_loader.py:加载
study.csv文件中的学习数据,进行预处理。 - data_analysis.py:分析学习数据,包括学习时间分布、学习成果统计和行为 模式分析。
- hive_integration.py:使用 Hive 查询学习数据并进行数据聚合,进一步 支持数据分析。
- hdfs_operations.py:在 HDFS 中上传和读取文件,如上传
study.csv并读取分析结果。
请你根据前面的项目背景与数据描述,在 PyCharm 中完成如下题目:
题目 1
在 data_loader.py 中,加载 CSV 文件的函数 load_data 使用 pandas 库来读取文件。请补全以下代码以完成 CSV 文件的加载:
def load_data(file_path):
data = pd.read_csv(__________)
return data答案
填空答案:file_path
题目 2
在 data_analysis.py 中,analyze_study_time 函数使用 groupby 方法按 student_id 汇总学习时长。请补全以下代码:
def analyze_study_time(data):
study_time_summary = data.groupby('student_id')[__________].sum().reset_index()
return study_time_summary答案
填空答案:'study_time'
题目 3
在 data_analysis.py 中,analyze_activity_type 函数统计每种活动类型的数量。请填空以完成 value_counts 调用:
def analyze_activity_type(data):
activity_summary = data[__________].value_counts().reset_index()
return activity_summary答案
填空答案:'activity_type'
题目 4
在 data_analysis.py 中,save_results 函数用于将分析结果保存到 CSV 文件。请补全以下代码以实现文件保存:
def save_results(data, output_file):
data.to_csv(__________, index=False)答案
填空答案:output_file
题目 5
在 hive_integration.py 中,connect_hive 函数连接到 Hive 数据库。请填空以指定默认的 Hive 主机和端口:
def connect_hive(host=__________, port=10000, database='default'):
conn = hive.Connection(host=host, port=port, database=database)
return conn答案
填空答案:'localhost'
题目 6
在 hive_integration.py 中,query_hive 函数用于执行 SQL 查询。请填空以获取查询结果:
def query_hive(conn, query):
cursor = conn.cursor()
cursor.execute(query)
return cursor.__________()答案
填空答案:fetchall
题目 7
在 hdfs_operations.py 中,upload_to_hdfs 函数上传文件到 HDFS。请补全以下代码,以指定 HDFS 客户端和上传路径:
client = InsecureClient(__________)
client.upload(__________, local_path)答案
填空答案:hdfs_url, hdfs_path
题目 8
在 hdfs_operations.py 中,read_from_hdfs 函数从 HDFS 读取文件内容。请填空以完成文件读取操作:
with client.read(__________) as reader:
return reader.__________()答案
填空答案:hdfs_path, read
题目 9
在主脚本中,调用 analyze_study_time 函数分析数据中的学习时长。请填空补全代码:
from data_analysis import analyze_study_time
study_time_summary = analyze_study_time(__________)答案
填空答案:data
题目 10
在主脚本中,调用 save_results 函数保存分析结果。请填空以指定保存路径:
save_results(study_time_summary, __________)答案
填空答案:'results/study_time_summary.csv'
三、数据分析挖掘(20 分,每题 2 分,共 10 题)
智能交通管理系统:分析交通流量数据,优化信号灯控制,减少拥堵
1. 项目背景描述
本项目的目标是开发一个基于数据分析与挖掘的智能交通管理系统,旨在通过对交通流量数 据的分析,优化城市信号灯的控制策略,从而减少交通拥堵。随着城市化进程的加快,城市 交通拥堵问题日益严重,影响了市民的出行体验、公共资源的利用效率和城市的可持续发展。
智能交通管理系统可以通过对历史和实时交通数据的分析,识别出高峰时段、拥堵路段、车 辆行驶模式等关键信息。基于这些数据,系统能够生成并调整信号灯配时方案,优先保障主 干道和繁忙路口的畅通,以最大限度提高交通流通率。同时,通过预测性分析,系统可以提 前识别潜在拥堵情况,并给出分流建议,提升整体出行效率。
最终目标是构建一个高效的信号灯控制系统,降低交通延误,减少车辆等待时间,改善空气 质量,并为市民提供便捷、安全的出行环境。
2. 项目目录结构
intelligent_traffic_management/
├── data/ # 数据文件夹
│ ├── raw_traffic_data.csv # 原始交通流量数据
│ ├── processed_traffic_data.csv # 预处理后的数据
│ └── traffic_model.pkl # 交通流量预测模型文件
│
├── src/ # 代码文件夹
│ ├── __init__.py # 初始化文件
│ ├── data_preprocessing.py # 数据预处理模块
│ ├── traffic_analysis.py # 交通流量分析模块
│ ├── signal_optimization.py # 信号灯优化模块
│ ├── model_training.py # 模型训练与预测模块
│ ├── evaluation.py # 效果评估模块
│ └── real_time_adjustment.py # 实时控制与调整模块
│
├── config/ # 配置文件夹
│ └── config.yaml # 配置文件(如数据库连接、模型参数等)
│
├── results/ # 分析和模型结果文件夹
│ ├── traffic_analysis_report.csv# 交通流量分析报告
│ ├── signal_optimization_log.csv# 信号灯优化日志
│ └── evaluation_metrics.csv # 效果评估指标
│
├── logs/ # 日志文件夹
│ └── project.log # 项目运行日志
│
├── notebooks/ # Jupyter notebooks(用于数据探索与可视化)
│ └── traffic_data_exploration.ipynb # 数据探索 notebook
│
├── tests/ # 测试文件夹
│ ├── __init__.py # 初始化文件
│ ├── test_data_preprocessing.py # 测试数据预处理模块
│ ├── test_traffic_analysis.py # 测试交通流量分析模块
│ ├── test_signal_optimization.py# 测试信号灯优化模块
│ └── test_model_training.py # 测试模型训练模块
│
└── README.md # 项目说明文档
3. 主要模块说明
- data_preprocessing.py:处理原始交通流量数据,进行数据清洗、异常值处理和 标准化,为分析和模型训练准备干净的输入数据。
- traffic_analysis.py:对交通数据进行深入分析,识别高峰时段、交通流量变化趋 势和拥堵路段。
- signal_optimization.py:基于流量分析结果,优化信号灯的控制策略,例如调整 红绿灯配时和信号优先级,提升通行效率。
- model_training.py:建立和训练交通流量预测模型,如时间序列模型或机器学习 模型,用于预测未来的交通流量,辅助信号控制。
- real_time_adjustment.py:实时调整模块,用于根据实时交通流量数据动态调整 信号灯策略,以应对突发状况和即时需求。
- evaluation.py:评估模型和信号控制策略的效果,包括交通拥堵情况、车辆通行 时间、信号灯调整的有效性等。
4. 其他文件说明
- config.yaml:用于存储项目的参数配置(如数据库路径、模型参数等)。
- project.log:记录项目的运行日志,包括数据处理、模型训练和信号灯调整的过 程。
- traffic_data_exploration.ipynb:Jupyter Notebook,用于进行数据的初步探索和 可视化,帮助更好地理解数据特征。
- tests/:包含各模块的单元测试文件,以确保各功能模块的正确性和稳定性。
请你根据前面的项目背景与数据描述,在 PyCharm 中完成如下题目:
题目 1
在 data_preprocessing.py 中,preprocess_data 函数使用 StandardScaler 对特征进行标准化。请填空补全代码:
from sklearn.preprocessing import _________
scaler = _________()
data[['traffic_volume', 'average_speed']] = scaler.fit_transform(
data[['traffic_volume', 'average_speed']]
)答案
填空答案:StandardScaler, StandardScaler
题目 2
在 traffic_analysis.py 中,analyze_peak_hours 函数用于计算高峰时段的平均交通流量。请填空补全代码:
peak_hours = (
data.groupby('hour_of_day')['__________']
.mean()
.sort_values(ascending=False)
)答案
填空答案:traffic_volume
题目 3
在 traffic_analysis.py 中,analyze_congestion_areas 函数识别拥堵路段。请填空以定义拥堵的标准(假设低于 10 km/h 为拥堵):
congestion = data[data['average_speed'] < __________]答案
填空答案:10
题目 4
在 signal_optimization.py 中,optimize_signal_timing 函数通过平均流量来调整信号灯。请填空补全代码:
avg_volume = location_data['__________'].mean()
if avg_volume > 1000:
optimization_strategy[location] = "延长绿灯时长 10 秒"答案
填空答案:traffic_volume
题目 5
在 model_training.py 中,train_traffic_prediction_model 函数使用 RandomForestRegressor 训练交通流量预测模型。请填空补全代码:
from sklearn.ensemble import __________
model = __________(n_estimators=100, random_state=42)答案
填空答案:RandomForestRegressor, RandomForestRegressor
题目 6
在 model_training.py 中,save_model 函数用于保存训练好的模型。请填空补全代码:
with open(file_path, 'wb') as f:
pickle.__________(model, f)答案
填空答案:dump
题目 7
在 real_time_adjustment.py 中,adjust_signal_timing_real_time 函数通过 traffic_volume 调整信号灯配时。请填空补全代码:
if traffic_volume > 1000:
print(f"路口 {location_id}:延长绿灯时长 10 秒")
elif traffic_volume < __________:
print(f"路口 {location_id}:缩短绿灯时长 5 秒")答案
填空答案:300
题目 8
在 real_time_adjustment.py 中,monitor_and_adjust 函数每隔一段时间执行实时调整。请填空补全代码:
while True:
for _, row in data.iterrows():
adjust_signal_timing_real_time(row['location_id'], row['traffic_volume'])
time.sleep(__________) # 每隔 60 秒更新一次答案
填空答案:60
题目 9
在主脚本中,调用 analyze_peak_hours 函数分析高峰时段。请填空补全代码:
from traffic_analysis import analyze_peak_hours
peak_hours = analyze_peak_hours(__________)答案
填空答案:preprocessed_data
题目 10
在主脚本中,调用 train_traffic_prediction_model 函数训练交通流量预测模型。请填空补全代码:
from model_training import train_traffic_prediction_model, save_model
model = train_traffic_prediction_model(__________)
save_model(model, 'data/traffic_model.pkl')答案
填空答案:preprocessed_data
四、数据可视化(15 分,共 1 题)
“智慧学习可视化分析”
1. 项目背景描述
随着教育信息化的不断发展,基于大数据的智慧学习逐渐成为现代教育的核心组成部分。 智慧学习结合了数据分析、机器学习和人工智能技术,通过对学习行为、学习成绩、学习习 惯等数据的分析,能够实现个性化的学习路径和学习策略优化,为学生提供更为精准的学习
建议。
在本项目中,智慧学习系统将使用大规模教育数据来挖掘学生的学习模式和行为偏好, 分析不同学习阶段和学习风格下的效果差异。这些数据为教师和教育管理者提供了科学依 据,能够帮助他们制定合理的教学方案,提升教育质量。
2. 数据分析与可视化
我们有以下数据样例,用于展示学生在不同学习活动上的时间分布情况:
| 学习活动 | 时间 (小时) |
|---|---|
| 阅读 | 50 |
| 练习 | 30 |
| 视频学习 | 40 |
| 测验 | 20 |
| 项目实践 | 60 |
题目要求:
请您依据上述背景和给出的数据,使用 Python 和 Matplotlib 创建柱状图和饼状图,表达 “学习活动时间比例”、” 学生在不同学习活动上的时间分布”, 请你根据理解,来对展示结 果进行分析与说明(备注:尽量分条目描述,1-5 条)
(正式比赛会给出相关数据,且仅有数据,备考情况,请自行搭建环境)
参考答案
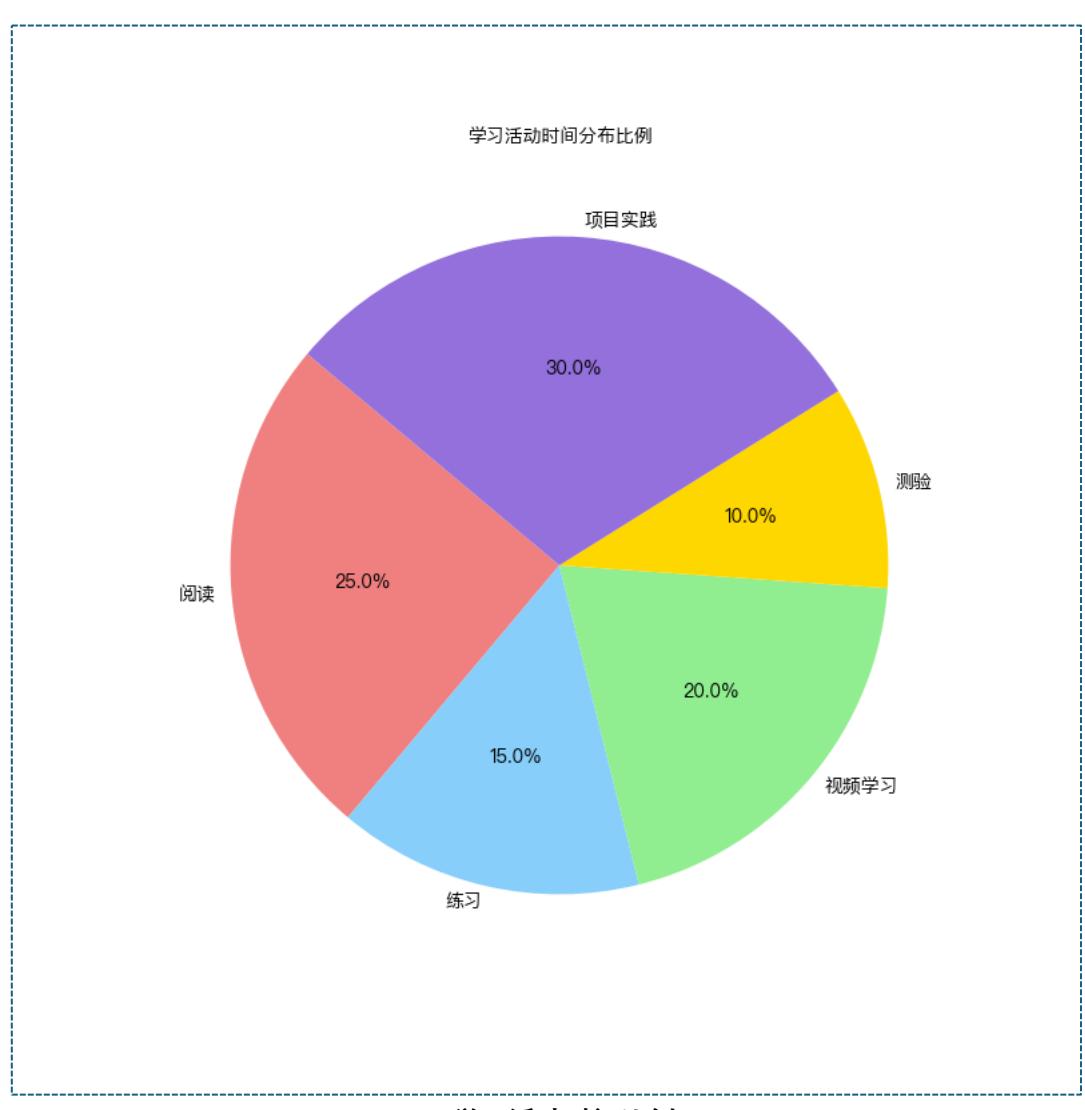
学习活动时间比例
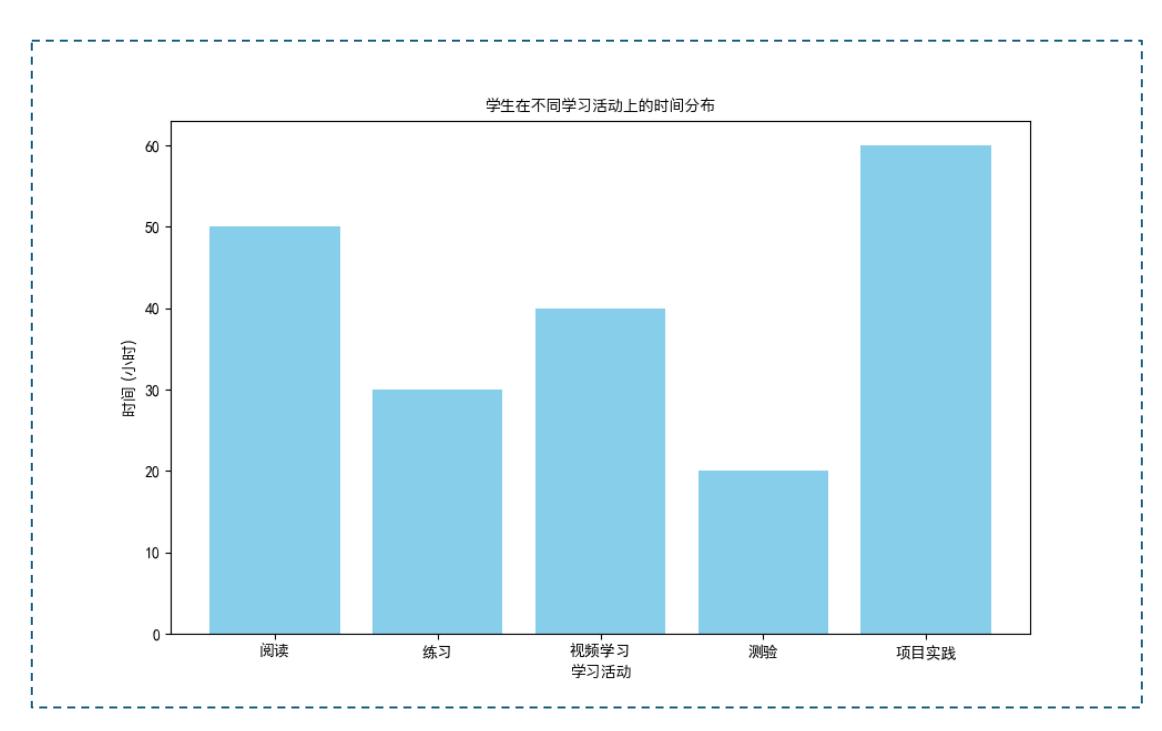
学生在不同学习活动上的时间分布
学习活动时间比例
- 饼状图显示,项目实践占据了总学习时间的最大比例,达到了 31.6%,是最耗时的活动。
- 阅读和视频学习也占据了较大比例,分别为 26.3%和 21.1%,说明学生在获取信息和知识 时倾向于利用这类活动。
- 练习和测验的时间比例相对较小,占总时间的 15.8%和 10.5%,这表明在实际测试和强化 训练方面的时间较少。
- 各活动的比例展示了学生学习行为的侧重点,实践与自学显然成为主流。
- 此比例分析有助于教育者了解学生在学习活动中的时间分配,从而在教学设计中平衡不 同活动类型。
学生在不同学习活动上的时间分布
- 从柱状图可以看出,学生在项目实践上的时间投入最多,达到 60 小时,远高于其他活动。
- 阅读和视频学习也占据了较多的时间,分别为 50 小时和 40 小时,显示出学生对这些活 动的重视。
- 相比之下,学生在练习和测验上的时间较少,尤其是测验时间,仅有 20 小时。
- 整体来看,时间分布呈现出向项目实践、阅读等活动倾斜的趋势,可能反映了学生对动手 实践和自主学习的偏好。
- 不同活动间的时间差异显示出学习活动的多样化需求,有助于了解学生的学习偏好以制 定相应的教学策略。
五、综合分析(10 分,共 1 题)
商超市场分析与智慧营销
商超的行业背景描述
北京某大型商超面临复杂的市场分析需求,希望通过对大数据的深度挖掘,获得关于消费者 行为、市场细分及竞争对手动态的洞察,从而优化商品陈列和营销策略。商超不仅需要了解 消费者的购买偏好和购物频率,还要识别不同消费群体的特征,制定精准的营销活动。同时, 监测竞争对手的促销动态和市场表现也至关重要,以便快速响应市场变化,保持竞争优势。
具体而言,商超的主要问题包括:
- 消费者行为识别:了解顾客在不同商品类别上的消费行为,如高频商品、季节性商 品和促销商品的需求波动。
- 精准市场细分:针对家庭主妇、上班族、年轻人等不同群体,识别他们的购物习惯 并推送有针对性的优惠信息。
- 竞争动态跟踪:通过监测其他商超的促销活动、特定商品的折扣率和价格变化,优 化自有商超的定价和促销策略。
- 实时数据处理:有效分析快速变化的销售数据,调整库存和补货,避免商品短缺或 库存积压。
请您依据上述行业背景分析,从技术视角给出合理的解决方案;
参考答案
使用大数据技术的解决方案
为解决上述问题,北京某商超可以利用大数据技术打造一个市场分析系统,实现消费者行为 洞察、市场细分和竞争动态跟踪。以下是该方案的具体技术思路:
1. 数据收集与存储
- 数据源:通过 POS 系统、会员管理系统、APP 以及微信公众号等收集销售、会员 和购物行为数据,了解消费者在不同品类商品上的购买行为。
- 数据存储:利用 HDFS 进行分布式存储,保障商超每日产生的海量数据可以安全 高效地存储并快速读取。
2. 数据预处理
• 清洗和整合:使用 ETL 工具清洗数据,去除重复记录并处理缺失值,确保数据的 完整性和准确性。
• 特征提取:从交易数据中提取商品类别、消费金额、购买频率、会员等级等特征, 为后续分析提供数据支持。
3. 消费者行为分析
- 数据分析和模式识别:使用 Spark、Hadoop 等分布式处理工具,对顾客的消费习 惯进行分析,识别高频购买的商品、季节性商品需求以及促销商品的销售趋势。
- 机器学习模型:使用聚类算法(如 KMeans、DBSCAN)进行市场细分,区分不同 消费群体并构建用户画像,为定制化营销活动提供依据。
4. 竞争对手分析
- 情报收集:从公开渠道(如社交媒体、竞争对手的网站、价格比较平台)获取竞品 信息,了解其他商超的促销活动和价格变化。
- NLP 分析:利用自然语言处理技术,对文本信息进行情感分析和关键词提取,帮 助分析竞争对手的市场策略和产品优劣。
- 市场趋势预测:基于时间序列模型预测特定商品的价格波动,为商超提供竞争性定 价建议。
5. 数据可视化
- 数据可视化工具:使用 Tableau 或 Power BI 创建实时可视化面板,显示消费者 偏好、促销效果和竞争动态。
- 自定义仪表盘:展示关键绩效指标(KPI),如日均销量、库存水平、促销效果等, 以便管理者快速了解业务情况。
- 自动报告生成:定期生成市场分析报告,包含销售趋势、市场份额和顾客反馈,以 支持商超的决策。
6. 技术架构概述
- 数据层:HDFS 存储所有数据,Kafka 处理实时数据流,Hive 和 Spark SQL 提供 查询支持。
- 分析层:Spark 负责批量处理和实时数据分析,使用 Scikit-learn 和 TensorFlow 进行市场细分和行为预测。
- 展示层:Tableau 和 Power BI 实现数据可视化,帮助决策者随时掌握市场动态和 消费者需求。
总结
通过大数据技术,商超可以构建一个智能市场分析系统,深入挖掘消费者行为、有效实施市 场细分和及时跟踪竞争动态,从而提升业务效率、优化库存管理,并提高整体市场竞争力。
六、职业素养(5 分)
职业素养模块评分标准
- 沟通表达:选手是否具备良好的语言表达能力,能否流畅、清晰地进行信息传达, 展现出理解和反馈的能力。
- 团队合作:选手是否能够与团队成员紧密合作,是否能在团队中发挥积极作用。
- 时间管理:考察选手的时间观念,是否按时完成任务,是否能够高效利用时间。
- 职业态度:选手的责任心和工作积极性,是否表现出较高的职业热情。
- 应急处理能力:面对问题或突发情况时,选手是否具备灵活应对、沉着处理的能 力。